code intelligence for AI coding agents
Know which tests a change can break, before you run a single one.
Hayvenhurst keeps a live graph of your codebase (every function, call, and import) and puts it to work: run only the tests a change can reach, hand your agent the exact slice of code it needs instead of the whole file, and let a fleet of agents edit in parallel without colliding. It indexes a 362-file repo in 0.65 s, re-parses only what changed, and caches per branch, so it stays current with no model, no GPU, and nothing to babysit. Your code never leaves the box.
measured, not marketed
Every number comes from a committed benchmark.
The comparison below runs against an embedding-based indexer on real open-source repos. Reproduce it yourself in 60 seconds. The harness ships in the repo.
| hayvenhurst | embedding-based indexer | |
|---|---|---|
| Cold index (hono, 362 files) | 0.65 s | 35.6 s (embeds 3,543 chunks) |
| Cold index (gin, Go) | 0.23 s | n/a |
| Cold index (django, 2,967 files) | 10.6 s | 260 s on fastapi, at ⅓ the file count |
| Cold index (kibana, 93,923 files) | 5.4 min · 3.8 GB RAM · linear | n/a |
| Query latency at 334k entities | 0.27 s | n/a |
| Branch switch (re-parse only the diff) | ~48 ms | re-syncs + re-embeds every switch |
| Revisit a previously-seen branch | 1 ms (cached) | 0.41 s |
| Retrieval coverage, novel symptom queries | 3 / 3 | 0 / 3 |
| Dependencies to run | none (one Rust binary + SQLite) | model + torch + vector store |
The asymmetry is architectural, not a tuning gap: an embedding indexer must
re-embed; we parse and cache per branch, and never embed at all.
Every harness ships in the repo under bench/.
see it
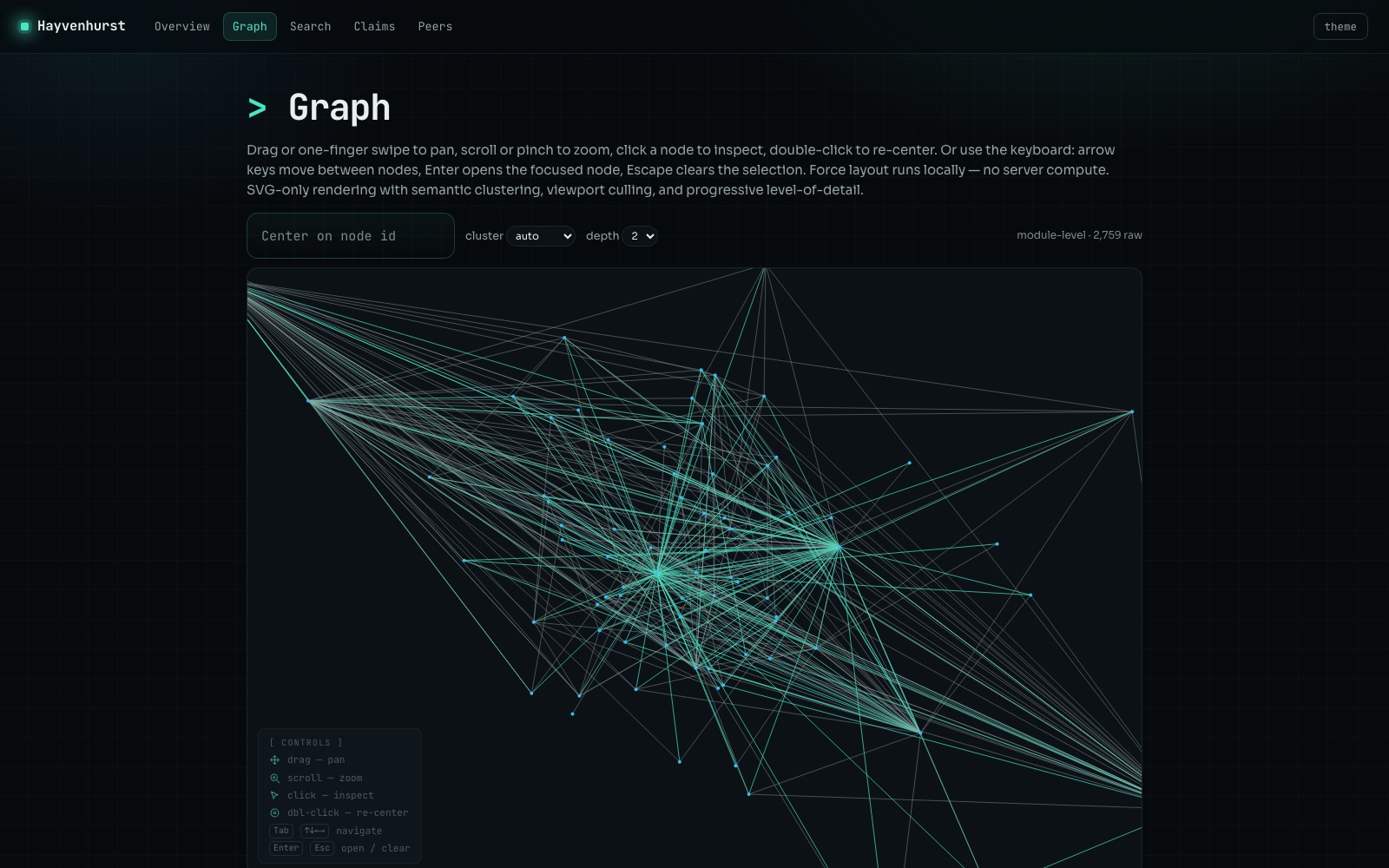
Your codebase, as a living graph.
This is the viewer the daemon serves at localhost:7777 showing
hono, indexed in 0.65 s: 2,185 entities
joined by 7,250 call and import edges, laid out by a local force simulation. SVG-only,
under 100 KB of JavaScript, no server compute.
what it does
A code graph your agents can actually use.
Grep finds text. Hayvenhurst answers structural questions (what calls this, what breaks if it changes, which tests can catch it) and stays current on every branch, automatically.
Run only the tests that can break.
hayven affected-tests fuses the static call graph with
runtime traces (what your code actually does when it runs) to select the
tests a change can reach, on Python (pytest) and TypeScript (vitest, bun test).
Static analysis alone missed the dispatch-reached tests entirely; the
trace-augmented map caught every one.
Precise slices, not whole files.
hayven context <symbol> returns the minimal graph slice an agent
needs: the entity, its real dependencies, line-exact. A drop-in proxy applies the
same trick to any Anthropic / OpenAI / Gemini traffic, automatically.
Parallel agents, no collisions.
An entity-scoped claim board lets a fleet of agents edit the same repo safely. Two agents can work different functions in one file, and work that would break another agent's assumptions is flagged before it happens.
realized conflict rate 2.4% vs ~22% naive · truly-independent work never blockedNever goes stale. Never phones home.
A native file watcher re-parses only what changed; every branch keeps its own cached index. Peers sync without a server via CRDTs. A representative day of sync measured at ~5.6 KB on the wire. Your code never leaves the box.
watcher idle CPU ≤ 0.0081% on 30K files · daemon RSS ~43 MBunder the hood
One Rust binary, one SQLite file, plain markdown.
The graph's source of truth is human-readable markdown in .hayven/;
SQLite is a rebuildable index on top. It runs on a $599 Mac mini, or a Raspberry Pi.
And it meets your code where it is: this month's TypeScript monorepo or a decade-old
require() codebase get the same graph.
┌─────────────────────────────────────────────┐
│ hayvend (Bun) │
agents │ CLI · HTTP API · CRDT state · claim board │
───────► │ SQLite index (FTS5) · .hayven/ markdown SoT │ ◄── peers
query └───────┬──────────────────┬───────────────┬───┘ (sync)
│ │ │
hayven-native (Rust) graph viewer trace collectors
parse · watch · infer localhost:7777 runtime call edges philosophy
Five principles, in priority order.
When they conflict, the earlier one wins.
Egalitarian by hardware tier
Useful on a Raspberry Pi and on a 4090. Nobody is locked out.
Data-efficiency first
Every byte on the wire must justify itself. Dial-up before fiber.
Local-first, cloud-optional
Your machine is the primary execution environment.
Original where it matters, boring where it doesn't
Custom CRDT serializer; off-the-shelf SQLite.
Distributable, not centralized
Every daemon is potentially a peer.
quickstart
Sixty seconds to a queryable graph.
Pre-release (0.x). Build from source with
Bun and a Rust toolchain.
Signed release tarballs land with v1.0.